




Author: Philip Tannor, Co-Founder & CEO at Deepchecks
The world of cybersecurity is constantly evolving with new types of attacks and vulnerabilities being discovered and exploited all the time. With the amount of potential threats and the ever growing quantities of data, there has been a significant increase in use of automated machine learning methods as an integral part of cybersecurity solutions. These models play important roles in network anomaly detection, malware detection and classification, spam detection and more.
In this post we will discuss the importance of testing machine learning models, and machine learning model monitoring in the field of cybersecurity. While there are many different components of testing and monitoring ML models, we chose to focus on some of the most common issues that come up in cybersecurity applications, that can be avoided or detected early on with the correct approach.
Evaluation Metrics
Let’s start off with determining what it is that we would like to monitor.
In the typical use case for ML models in cybersecurity, given a sample of a file, or a network traffic dump, we want to decide whether the activity seems normal, or whether something fishy is going on (anomaly). By definition, an anomaly is out of the ordinary, and thus the datasets used for training are generally imbalanced. Therefore, accuracy is not a good enough metric to evaluate the model’s performance, and there is a need for a more fine grained analysis using metrics such as precision, recall, ROC curve, and more.
The Tradeoff Between False Positives and False Negatives
Have you ever disabled your antivirus after it blocked your perfectly normal activity?
If so, you can be sure you’re not the only one.
When software systems such as AVs make too much noise, we stop trusting them, and we may even prefer to continue on without them if they disrupt our workflow. On the other hand, if they do not detect a malicious backdoor on our file system that’s even worse. Thus, it is essential for cybersecurity defense systems to strike the right balance between false positives and false negatives. Finding the right balance can be done by threshold moving while using the roc curve and the precision recall curve to select the optimal threshold. Note that we can decide to introduce a more silent response for cases where the positive prediction has a low confidence value.
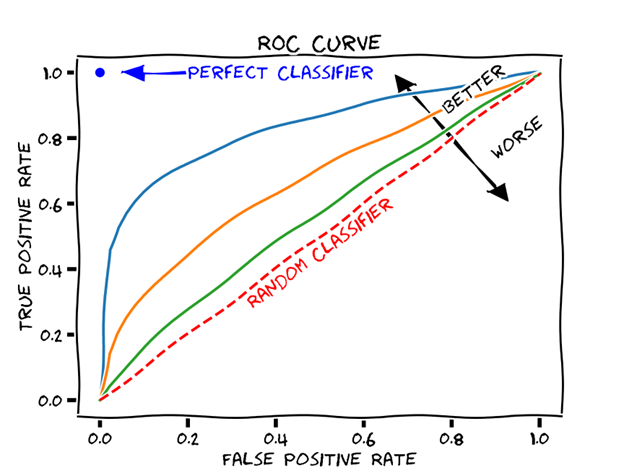
The ROC curve can help find the optimal balance between FP and FN (source)
Data Drift and Concept Drift
Most ML models last a limited amount of time in production, and then they need to be replaced with a more up-to-date model. This is especially true in applications where the data and what we are trying to detect (the concept) constantly changes. In the context of cybersecurity, the ever-evolving types of vulnerabilities and malwares may redefine the kinds of behaviors that we should consider malicious.
Additionally, fluctuations and shifts in “normal” behavior like increased website traffic after an advertisement campaign, or new types of network activity following the introduction of a new DB in the LAN can result in incorrect predictions as well.
In order to detect concept drift quickly we need to continuously monitor the model’s predictions and the input data to detect significant shifts in the distributions.
Schema Change
The data we feed our ML model is dynamic. It can come from a third party source that we have no control over, it may be affected by a software update or a DB refactoring in your own company. In short we cannot be certain that the format of the data that we get during training will remain constant in the “real world” forever. The problem is, that any minor change in the structure of the data may have a dramatic effect on the model’s performance in production. Imagine for example that there is a minor column rename from “dst ip” to “dst ipv4”. When processing the data and feeding it to our model for prediction we may end up losing important information, or misinterpreting the data. Thus it is essential to monitor the data schema and detect any possible changes early on.
assert df1.dtypes.equals(df2.dtypes)
simple one-liner for detecting schema changes with pandas
Calibrating Your Model
A calibrated ML model is one for which the prediction score before discretization can be used as a measure of the model’s confidence. This can be especially useful in applications such as network anomaly detection or malware detection, since we may have an arsenal of possible reactions. We would not be interested in sounding all the alarms for every potential threat with a mere 51% confidence level. Thus, given a calibrated model, you can decide whether to send a sample of a potential threat for further investigation, actively block a specific IP address or trigger a notification to the IT team, all based on the confidence level of the model’s prediction. On the other hand, treating the scores of an uncalibrated model as a confidence measure and acting on it could result in disproportionate reactions of your system.
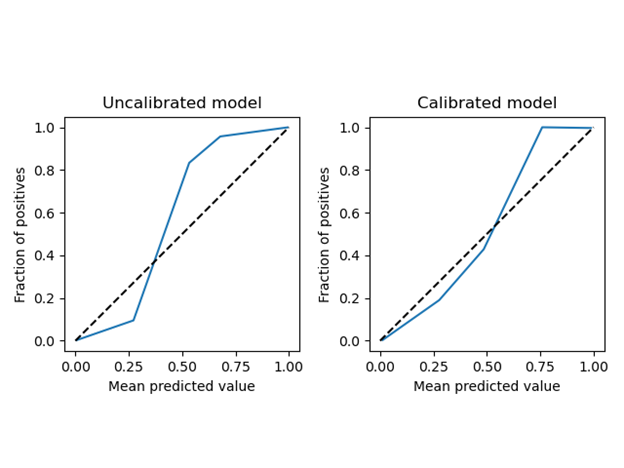
Calibrated and uncalibrated reliability diagrams. A calibrated curve is one where the predicted value (x) reflects the actual probability that an example’s actual label is “true” (y), thus the curve y=x is perfectly calibrated (image by author)
from sklearn.ensemble import RandomForestClassifier
from sklearn.calibration import calibration_curve, CalibratedClassifierCV
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
clf2 = CalibratedClassifierCV(clf, cv=”prefit”)
clf2.fit(X_validation, y_validation)
prob_true, prob_pred = calibration_curve(y, clf2.predict_proba(X)[:, 1])
plt.plot(prob_pred, prob_true)
Code example for calibrating a random forest binary classification model
Conclusion
In conclusion, testing and monitoring machine learning models for cybersecurity applications can be challenging, but these are extremely important practices that enable you to be in control of your models and detect possible issues early on before any harm is done. With products such as Deepchecks, it is easier than ever to monitor and test your ML models with seamless integration.
Further Reading
validating your ML model before deploying to production
Machine Learning Approach for IP-Flow Record Anomaly Detection
A holistic review of Network Anomaly Detection Systems













